
Vanta
25% off on any plan
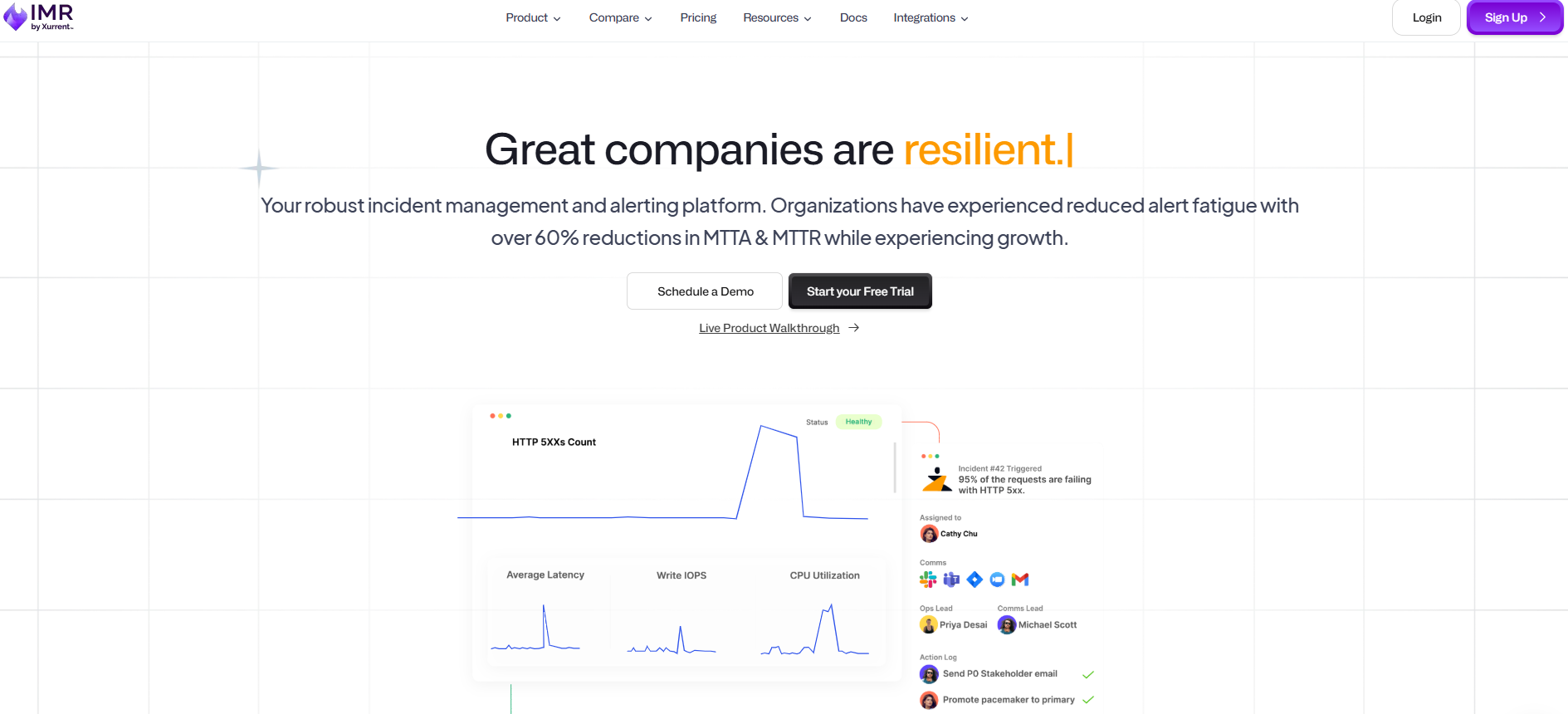

Zenduty is an end-to-end incident management and response platform built for engineering and DevOps teams that can’t afford downtime. The idea is simple: alert the right person, at the right time, through the right channel-whether that’s Slack, Microsoft Teams, a phone call, SMS, or email-so that critical production issues are addressed before customers are affected. The platform covers the entire incident lifecycle, from intelligent alerting and on-call scheduling to collaborative response, postmortem generation, and analytics. Teams using Zenduty report over 60% reductions in both MTTA and MTTR, which for high-traffic businesses translates directly into fewer outages and better SLAs.
On the technical side, Zenduty integrates with over 150 tools across monitoring, communications, and ticketing, including Datadog, Prometheus, Grafana, AWS CloudWatch, Jira, and more, making it easy to integrate into an existing stack without having to rebuild workflows from scratch. The built-in AI engine, ZenAI, handles scheduling optimization, payload analysis, and automatic postmortem generation, reducing the manual work that slows teams down during and after incidents. The platform is SOC 2 certified and ISO 27001 compliant, and a free trial is available with no credit card required.
Everything you need for modern incident management:
How Xurrent IMR's incident management works:
Since November 2025, Zenduty has officially rebranded as Xurrent IMR (Incident Management and Response), bringing it into the broader Xurrent ecosystem while retaining all existing workflows, integrations, and data intact.
Xurrent IMR is an end-to-end incident management platform that provides real-time alerts about critical events from monitoring, ticketing, and support systems, helping teams manage incidents, delegate tasks effectively, and meet their SLAs. It is designed primarily for SRE engineers, DevOps teams, and IT Operations who need a reliable system that never lets a critical incident slip through.
On-call scheduling and escalation policies are at the heart of what the platform does. Teams can deploy customized, data-driven on-call rotations to ensure 24/7 operational coverage for major incidents. Escalation chains are fully configurable: if the first responder does not acknowledge, notifications automatically cascade to the next person in line until someone picks up.
Built-in alert correlation groups related alerts together and cuts through notification noise, so teams aren't responding to the same underlying problem multiple times under different forms. This is one of the more tangible differentiators compared to basic monitoring setups.
Native incident response within Slack, Microsoft Teams, and Google Chat means the entire incident lifecycle can be managed without switching tools. Xurrent IMR also creates and syncs dedicated Jira tickets automatically when an incident is triggered.
Playbooks let teams attach standard operating procedures directly to alert triggers, automating the sequence of actions that need to happen when something goes wrong. Paired with the workflow automation engine, they dramatically reduce manual coordination during high-pressure situations.
The post-incident management module includes AI-generated summaries and customizable postmortem templates, making it easier to document root causes, capture lessons learned, and avoid repeat incidents.
The platform integrates with over 150 popular monitoring and ticketing tools, including Datadog, AWS CloudWatch, Grafana, New Relic, Prometheus, Sentry, and many others. An open API covers custom integration needs for teams with more specific requirements.
Rounding out the feature set: status pages, maintenance windows, SLA tracking, stakeholder communication templates, and advanced analytics that provide engineering and operations leaders a real-time view of production health across all services.
Xurrent IMR offers three pricing tiers, billed monthly or annually (with a 16% discount for annual billing). A 14-day free trial of the Growth plan is available with no credit card required.
| Plan | Price | Users | Teams | Support |
|---|---|---|---|---|
| Starter | $6 per user per month | Up to 5 | 1 team | Community support |
| Growth | $16 per user per month | Up to 50 | Up to 5 teams | Business hours (9 a.m. to 5 p.m.) |
| Enterprise | Custom pricing | Unlimited (min. 80) | Unlimited | 24/7 priority support |
All plans include alert correlation, advanced alert rules, analytics, incident response via Slack/Teams/GChat, escalation policies, SLA tracking, playbooks, postmortem templates, and API access. The main differences between tiers come down to team size, support level, and add-ons.
| Feature | Starter | Growth | Enterprise |
|---|---|---|---|
| SSO | Not included | Included | Included |
| Status Pages | Not included | Add-on ($10,000/year) | Included |
| Customer Success Manager | Not included | Shared | Dedicated |
| Call/Text Message Limits | 100 per user per month (US, CA, IN) -25 elsewhere | Unlimited | Unlimited |
1️⃣ If you are a freelancer or consultant:
Whether you're working alone or with a very small team, you probably don't need the full capabilities of an enterprise incident management platform. That said, if you're managing infrastructure for clients or ensuring uptime for a SaaS product you've built, having a system in place is essential. Instatus is worth checking out. It focuses on status pages and basic incident communication rather than on-call orchestration, which suits independent operators who need a simple, credible way to keep clients informed when something goes down. Setup is quick, pricing is affordable, and there’s virtually no operational overhead. UptimeRobot takes a different approach: continuous uptime monitoring with alerts when a site or service goes offline. It won’t manage the incident response workflow, but for a freelancer maintaining client websites or APIs, it provides an early warning system at a cost that’s hard to beat. If your work involves maintaining cloud infrastructure for clients and you occasionally need to coordinate with a small team, Sentry is another option worth considering. It focuses more on application error tracking than on-call management, but it catches issues before they become incidents-which, for a solo operator, is often more valuable than a sophisticated escalation policy.
2️⃣ If you are a startup:
Startups tend to move fast and break things, sometimes on purpose. At this stage, the priority is to have clear visibility into what’s breaking and a reliable way to alert the right engineer when it matters. Datadog is the natural choice in this category. Most growth-stage engineering teams already use it for monitoring, and its incident management features have matured significantly. It doesn’t replace Xurrent IMR’s on-call depth, but if your team is already paying for Datadog observability, the incident management layer may be sufficient for a while. The integration between the two tools is also native and well-documented. Sentry is a good fit for startups building web and mobile applications. Its Focus on error tracking, performance monitoring, and release health provides engineering teams with actionable context before an incident escalates-a different approach than reactive alerting, but complementary. For startups specifically concerned about infrastructure reliability and multi-cloud visibility, Dotcom-Monitor offers synthetic monitoring and performance testing capabilities that can proactively identify issues before they impact users.
3️⃣ If you are an SMB or mid-market company:
At this scale, the real challenge lies in coordinating across multiple teams, ensuring clear ownership of services, and holding people accountable when things go wrong. A lightweight tool will quickly reach its limits. Datadog remains highly relevant here, particularly for organizations with complex infrastructure. Its combination of metrics, logs, traces, and incident management in a single platform reduces the number of tools the ops team has to maintain-a real operational benefit at this scale. Instatus can serve as a complementary public-facing layer: while Xurrent IMR handles internal incident response, Instatus manages external communication with customers and stakeholders. At the mid-market scale, customer trust during incidents matters just as much as resolution speed, and having a clean, branded status page goes a long way. For SMBs that are also investing in ITSM and broader service management, the Xurrent ecosystem itself (through Xurrent ITSM) becomes relevant as a natural extension of Xurrent IMR, given that the two products are being built to work alongside each other as a connected incident management and service operations platform.
Otherwise, these other software programs may also be a good alternative to IMR (formerly Zenduty).No resources currently available.